
Ever wondered how spellchecks and auto-corrections in your mobile phones bails you out by automatically suggesting the words that you were just about to type?
I’ve come across so many amazing functionalities in Python but the fuzzywuzzy package in particular caught my interest. So i decided to write a blog about this topic and share it to wider network.
Down below are the sub topics of this blog :
Levenshtein Distance
Fuzzywuzzy Package
Some Examples
End Notes
Levenshtein Distance
The concept of Levenshtein Distance sometimes also called as Minimum Edit distance is a popular metric used to measure the distance between two strings. It is calculated by counting number of edits required to transform one string into another. The edits could be one of the following:
- Addition of a new letter.
- Removal of a letter.
- Substitution
Mathematical formula behind the calculation goes by something like this.
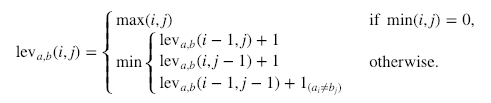
The formula above contains too many notations and subscripts too wrap one’s head around. I will quickly explain this by simple demonstration. Consider below the two strings ‘Shallow’ and ‘Follow’.
Following are the 3 simple edits required to change the 1st string to the other.
Edit 1 : Remove the 1st letter ‘S’.
Edit 2 : Substitute ‘h’ with ‘F’.
Edit 3 : Substitute ‘a’ with ‘o’.
And there we have it the Levenshtein distance between the two strings ‘Shallow’ and ‘Hallow’ is 3.
Now, there could be multiple ways of transitioning from one word to another but Levenshtein distance chooses the smallest possible path.
I have written a code in order to calculate the Levenshtein Distance for any two given strings. I highly recommend you to go through it. You can find the links to my notebook down below. Feel free to try out some other combinations and do let know if you find this helpful in the comment section.
Levenshtein Distance Calculation in Python : Link
Also, to understand the calculations in more details and to make sense of the bizarre mathematical formula shown above do watch this video. Very well explained, very intuitive and I highly recommend you to go through it once.
Fuzzywuzzy Package
The concept of fuzzy matching is to calculate similarity between any two given strings. And this is achieved by making use of the Levenshtein Distance between the two strings.
fuzzywuzzy is an inbuilt package you find inside python which has certain functions in it which does all this calculation for us. I’m going to discuss four of them which are as follows:
fuzz.ratio()
fuzz.partial_ratio()
fuzz.token_sort_ratio()
fuzz.token_set_ration()
Note : To use this you have to first install this package. Here’s how you do it.
pip install fuzzywuzzy
Examples
You may need to restart your kernel post installation.
ratio()
from fuzzywuzzy import fuzz
fuzz.ratio(‘My name is Sreemanta’,’My name is Sreemanta Kesh’)
Output : 89
The output is indicative of the fact that both the strings are 89% similar. Let us try some more examples.
print(fuzz.ratio(‘My name is Sreemanta’,’My name is Sreemanta ‘))
print(fuzz.ratio(‘My name is Sreemanta’,’My name is Sreemanta’))
Output : 98
Output : 100
fuzz.ratio() returns 100% only when it finds exact match. The 2nd example stated is an exact match where as the 1st one differs by a space.
fuzz.ratio(‘My name is Sreemanta’,’Sreemanta name is My’)
Output : 45
This tells us that order of the string also matters while comapring.
partial_ratio()
Lets perform the same example using partial_ratio() method.
print(fuzz.partial_ratio(‘My name is Sreemanta’,’My name is Sreemanta Kesh’))
print(fuzz.partial_ratio(‘My name is Sreemanta’,’My name is Sreemanta ‘))
Output : 100
Output : 100
Notice that the given strings are not same in either of the two cases still it gives a 100% match. This is because partial_ratio() is just checking if either of the string is a sub string of the other. Down below is another example to confirm the same
fuzz.partial_ratio(‘New York City’,’New York’)
Output : 100
token_sort_ratio()
fuzz.token_sort_ratio(‘My name is Sreemanta’,’Sreemanta name is My ‘)
Output : 100
This result is sharply different from the one observed when same command was run with ratio() method which yielded 45% match.
fuzz.token_sort_ratio(‘My name is Sreemanta’,’sreemanta name is My ** ‘)
Output : 100
From the above two example we can conclude that
- Order of the words does not matter.
- It also ignores punctuation.
It follows the concept of tokenization where the strings are converted in to tokens and then they are sorted in alphabetical order and thereafter the comparison happens.
token_set_ratio()
print(fuzz.token_sort_ratio(‘My name is Sreemanta’,’Sreemanta name is My Kesh ‘))
print(fuzz.token_set_ratio(‘My name is Sreemanta’,’Sreemanta name is My Kesh ‘))
Output : 89
Output : 100
token_set_ratio() takes a more flexible approach than token_sort_ratio(). Instead of just tokenizing the strings, sorting and then pasting the tokens back together, token_set_ratio performs a set operation that takes out the common tokens (the intersection) and then makes fuzz.ratio(). Extra or same repeated words do not matter.
fuzz.token_set_ratio(‘Jingle Bells’,’ Bells Jingle Bells’)
Output : 100
End Notes
When I performed fuzzy matching exercise first time I pondered over the following two questions
- How Levenshtein Distance (LD) is being used to calculate the ratio?
- What is this ratio?
After doing a small research I was able to unearth the formula.
Ratio = (len(str1)+len(str2) – LD) / (len(str1)+len(str2))
Exercise for you : Try to embed this formula into my Levenshtein Notebook
There are some more functionalities present inside the fuzzywuzzy package such as WRatio(), URation etc. I urge you to explore more.
Personally I have used fuzzy matching in my organization, where the aim was to map ‘Vendor Names’ with it’s ‘Invoice Reference’ and check for duplicity by setting the fuzz.ratio() threshold to 96%. This methodology has a various other important application across the industries like spell checks as listed in the beginning, CRM applications, Bioinformatics etc.
Do comment your thoughts below.

